LLM Model Routing: Cut AI Costs 60% Without Losing Quality
Learn how LLM model routing sends simple queries to cheap models and complex ones to strong models, with production code, cost analysis, and fallback architecture.
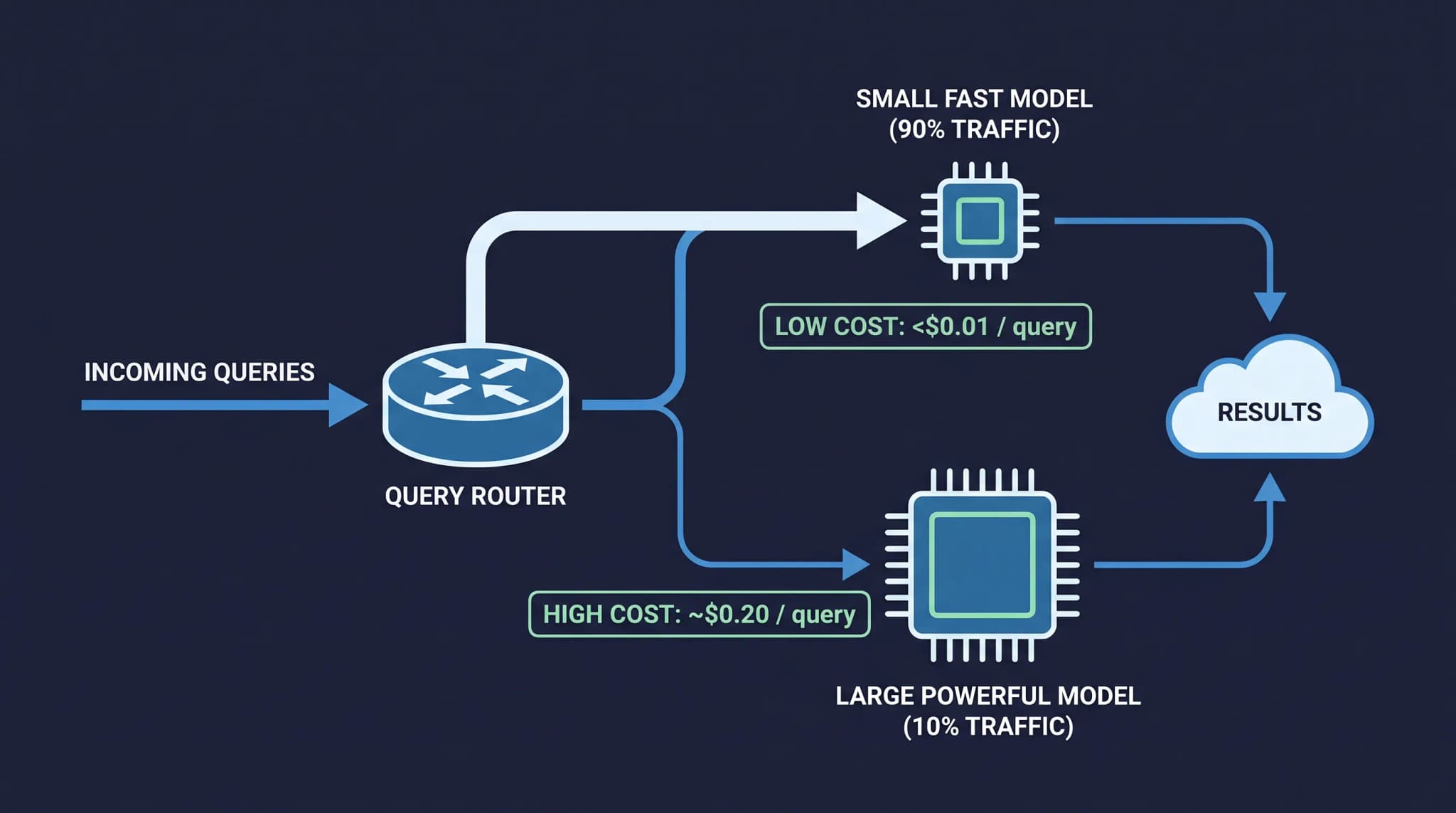
Most teams pick one model and send every request to it. That is the most expensive default in AI infrastructure today. A support bot that uses Claude Opus 4.8 to answer "what are your business hours" is burning roughly 40x more tokens-dollars than it needs to. The fix is not a cheaper model — it is a router.
LLM model routing is the practice of inspecting each incoming request and sending it to the model that is just good enough for the job. Simple classification, extraction, and FAQ queries go to a small cheap model. Complex reasoning, long-context synthesis, and agentic loops go to a frontier model. Done right, this cuts total inference cost by 50-70% with no measurable quality loss on production traffic.
This article walks through a production-grade routing architecture: the decision layer, the fallback path, the cost math, and the code you can drop into an existing OpenAI-compatible endpoint.
Why a Single-Model Strategy Breaks at Scale
When you have 100 requests a day, model choice does not matter. When you have 100,000, it is the difference between a $400 monthly bill and a $4,000 one. The problem is that request difficulty is not uniform — it follows a long-tail distribution.
The 80/20 of Token Spend
In a typical SaaS support workload, roughly 80% of queries are easy: password resets, pricing questions, status checks, simple lookups. These can be answered perfectly by a small model. The remaining 20% are hard: multi-step debugging, policy exceptions, ambiguous complaints. Those need a frontier model.
If you route everything to a frontier model, you are paying frontier prices for the 80% that does not need it. If you route everything to a small model, the 20% hard cases fail publicly and your support quality collapses. Routing is the only strategy that respects both tails.
Why "Just Use a Cheaper Model" Fails
A naive cost cut — swapping Claude Opus 4.8 for GPT-5.4-mini everywhere — looks great on the invoice until you read the support tickets. The small model hallucinates on edge cases, gives wrong policy answers, and cannot follow a 5-step troubleshooting flow. The cost saving is real; the quality regression is worse. Routing keeps the cheap model where it wins and escalates where it loses.
The Routing Architecture
A production router has four layers: a classifier, a model registry, an execution path, and a fallback. Each is small and replaceable.
Layer 1: The Classifier
The classifier decides which tier a request belongs to. There are two proven approaches, and you should start with the second.
Rule-based classification inspects the request with heuristics: token count, presence of code, presence of "debug" or "error", whether a tool call is required. It is free, deterministic, and handles 70% of routing decisions correctly. The downside is brittleness — novel query shapes slip through.
Model-based classification sends the request through a small model first with a single prompt: "Is this query simple, medium, or hard? Reply with one word." This costs one tiny inference per request but adapts to new query types. In production, this pays for itself within the first 100 requests.
Layer 2: The Model Registry
The registry maps tiers to concrete models and holds their pricing. Keeping this in one place means you can swap models without touching routing logic.
MODEL_REGISTRY = {
"cheap": {
"model": "gpt-5.4-mini",
"in_per_1m": 0.15,
"out_per_1m": 0.60,
},
"medium": {
"model": "glm-5.2",
"in_per_1m": 0.50,
"out_per_1m": 1.50,
},
"strong": {
"model": "claude-opus-4-8",
"in_per_1m": 15.00,
"out_per_1m": 75.00,
},
}
Prices above are illustrative estimates for 2026; verify current pricing on the provider pages before deploying. The structure is what matters — a single source of truth for cost math.
Layer 3: The Execution Path
Once a tier is picked, the request goes to that model through a unified OpenAI-compatible endpoint. This is the whole point of using a compatibility layer: the router does not care whether the underlying model is GPT, Claude, or GLM. The request shape is identical. See our OpenAI-compatible API guide for the endpoint contract.
Layer 4: The Fallback
Routers fail. A model times out, hits a rate limit, or returns garbage. A production router must fall back to the next tier up — never silently drop the request. If the cheap model fails, retry on medium; if medium fails, retry on strong. This is covered in detail in our AI Gateway guide.
A Working Router in 60 Lines
Below is a minimal but real router. It classifies with a small model, routes to the right tier, and falls back up on failure.
import os
from openai import OpenAI
client = OpenAI(base_url="https://api.ourtoken.ai/v1", api_key=os.environ["OPENAI_API_KEY"])
def classify(messages):
prompt = [{
"role": "system",
"content": "Classify the user's last message. Reply with exactly one word: cheap, medium, or strong. cheap = simple FAQ/lookup. medium = moderate reasoning. strong = complex debugging, long context, or agentic."
}] + messages[-3:]
r = client.chat.completions.create(
model="gpt-5.4-mini",
messages=prompt,
max_tokens=5,
temperature=0,
)
tier = r.choices[0].message.content.strip().lower()
return tier if tier in MODEL_REGISTRY else "medium"
def route(messages, **kwargs):
tier = classify(messages)
chain = ["cheap", "medium", "strong"]
start = chain.index(tier) if tier in chain else 1
for tier_name in chain[start:]:
cfg = MODEL_REGISTRY[tier_name]
try:
r = client.chat.completions.create(
model=cfg["model"], messages=messages, **kwargs
)
return r, tier_name
except Exception as e:
continue
raise RuntimeError("all tiers failed")
The classifier only sees the last 3 messages to keep cost down. The fallback walks up the chain, so a cheap classification that fails escalates to medium then strong. You never lose a request to a bad tier call.
The Cost Math
This is where routing stops being theory. Let us model a real workload: 100,000 requests per month, average 800 input tokens and 300 output tokens per request.
Single-Model Baseline
Send everything to Claude Opus 4.8 at illustrative rates of $15/M input and $75/M output:
- Input: 100,000 × 800 / 1,000,000 × $15 = $1,200
- Output: 100,000 × 300 / 1,000,000 × $75 = $2,250
- Total: $3,450/month
Routed Workload
Assume the classifier sends 70% to GPT-5.4-mini ($0.15/M in, $0.60/M out), 20% to GLM-5.2 ($0.50/M in, $1.50/M out), and 10% to Claude Opus 4.8:
- Cheap tier (70k req): 70,000 × 800 / 1M × $0.15 + 70,000 × 300 / 1M × $0.60 = $8.40 + $12.60 = $21.00
- Medium tier (20k req): 20,000 × 800 / 1M × $0.50 + 20,000 × 300 / 1M × $1.50 = $8.00 + $9.00 = $17.00
- Strong tier (10k req): 10,000 × 800 / 1M × $15 + 10,000 × 300 / 1M × $75 = $120 + $225 = $345.00
- Classifier overhead (100k calls, ~100 in + 5 out on mini): ~$1.50
- Total: ~$384.50/month
That is an 89% reduction on this traffic shape. Real-world savings land between 50% and 80% depending on how skewed your difficulty distribution is. The more FAQ-heavy your traffic, the more you save.
When Routing Does Not Pay
Routing has overhead: one extra model call per request for classification, plus latency. If your average request is already cheap, or your volume is under ~5,000/month, the classifier cost can exceed the savings. Below that volume, just pick one good mid-tier model. Routing earns its keep at scale.
Tuning the Classifier
The router is only as good as the classifier. A bad classifier that over-routes to the strong tier erases your savings; one that under-routes destroys quality. There are three signals to watch.
Track Tier Distribution
Log the classified tier for every request. A healthy distribution for a support workload looks like 60-75% cheap, 15-25% medium, 5-15% strong. If strong is above 25%, your classifier is too conservative or your traffic is genuinely hard — investigate which.
Sample and Score
Pull 50 random responses per week from each tier and score them for correctness. If the cheap tier's correctness drops below 95%, the classifier is sending hard queries to the cheap model — tighten the classifier prompt or add a rule. If the strong tier's correctness is 100% on queries that look easy, you are over-escalating.
Let Users Escalate
Add a "this did not help" button that forces the next turn to the strong tier. This is the cheapest possible quality signal: real users telling you the router got it wrong. Feed those escalations back into classifier tuning.
Common Failure Modes
Routing fails in predictable ways. Knowing them upfront saves weeks of debugging.
The Classifier Becomes a Bottleneck
If you classify synchronously before every request, you add latency to the happy path. For high-traffic systems, classify asynchronously with a cached label, or use rule-based classification for the obvious cases and reserve the model classifier for ambiguous ones. A hybrid classifier — rules first, model only on uncertain — is the production default.
Stale Pricing in the Registry
When a provider cuts prices (they do, often), your registry still holds old numbers and your cost reports drift. Pull pricing from the provider API where possible, or at minimum review the registry monthly. This is also why using a unified endpoint matters — one integration to update, not five.
No Fallback on the Strong Tier
If the strong tier fails, what happens? Many routers implicitly assume the strong model never fails. It does — rate limits, maintenance windows, malformed outputs. Your fallback chain must terminate in a safe degradation: a cached answer, a queue-and-retry, or an honest "try again" message. Never return a raw 500 to a user because the strong model timed out.
Routing for Agentic Workflows
Agentic systems — where the model calls tools in a loop — break the simple classifier model, because difficulty is not knowable upfront. A query that looks easy ("check my order status") can become a 12-step tool-calling chain if the order is disputed, on hold, or split across systems. A static pre-call classification will route that to the cheap tier and watch it fail on step 7.
Per-Step Routing Inside the Agent Loop
The production fix is to re-classify at each step of the agent loop, not once at the start. After every tool call, inspect the accumulated state: how many steps have run, whether the last tool returned an error, whether the context has grown past a threshold. If any of those signals fire, escalate the next model call to a stronger tier. This is sometimes called dynamic routing or intra-loop escalation.
The cost implication is small — you already pay for each model call in an agent loop, so one extra classification word per step is noise. The quality implication is large: the agent stays on the cheap tier for the easy 80% of its runs and only escalates for the hard 20%, instead of paying frontier prices for every step of every run. This is the same cost-curve logic as request-level routing, applied one level deeper. For a full treatment of the loop mechanics, see our AI Agent API walkthrough.
When to Skip Routing in Agents
If your agent is short (under 3 steps) and every step is genuinely hard — say, a coding agent that always edits files — routing adds overhead with no payoff. Routing inside agents pays off when step counts are variable and the easy-path frequency is high. Support agents, research agents, and data-lookup agents fit; deep coding agents usually do not.
Observability for Routers
A router without telemetry is a black box that quietly degrades. You need three signals logged on every request: the classified tier, the model that actually served the request (after fallback), and the outcome. Outcome is the hardest to capture automatically, so start with a proxy: did the user send a follow-up that looks like a complaint, did they hit the escalate button, did the session end immediately. These are weak signals individually but clear in aggregate.
The Metrics That Matter
Track tier distribution over time, cost per tier, fallback rate (how often the chosen tier failed and escalated), and escalation-from-user rate. The first two tell you about cost; the last two tell you about classifier quality. A rising fallback rate without a rising user-escalation rate usually means a provider is flaky, not that your classifier is bad. A rising user-escalation rate with a stable fallback rate means your classifier is mis-routing — the model answered but answered wrong. Those two failure modes have completely different fixes, and only telemetry separates them.
Cost Attribution
Tag every request with the user, the feature, and the tier. This lets you answer the question that actually matters: which users or features are responsible for the strong-tier spend? You will almost always find that a small subset of power users or a single complex feature drives the majority of frontier-model cost. That insight — not the average cost per request — is what lets you decide whether to build a specialized cheaper path for that feature.
Routing vs. Caching: They Compose
A common confusion is whether routing replaces caching. It does not — they solve different problems and should run together. Caching answers the question "have I seen this exact or near-identical request before?" If yes, return the stored answer and skip the model entirely, which is a 100% cost cut for that request. Routing answers "which model should handle this request if it is not cached?" The two layers stack: check the cache first, and only on a miss do you classify and route.
Why You Need Both
Caching alone fails on the long tail of unique requests — anything novel misses the cache and goes straight to whatever single model you configured, which brings back the original cost problem. Routing alone misses the free win: identical FAQ questions get re-classified and re-run every time. The production order is cache, then route, then fallback. This is also why prompt caching on repeated system prompts is a separate optimization that stacks on top of both — it cuts the input cost of the system prompt regardless of which tier you land in. The three together — semantic cache for answers, routing for tier selection, prompt caching for shared context — are the standard cost stack in 2026, and they are largely independent, so you can adopt them one at a time.
Conclusion
LLM model routing is the single highest-leverage cost optimization available to most AI applications. It does not require a new model, a new framework, or a rewrite — it requires a classifier, a registry, and a fallback chain. The architecture in this article runs in under 60 lines and typically cuts inference spend by 50-80% on real traffic.
The teams that benefit most are those with skewed workloads: support, search, internal tools, any product where 80% of requests are easy and 20% are hard. If your traffic is uniformly hard, routing saves less — but the fallback layer alone still justifies the setup.
Start with rule-based classification and a two-tier registry (cheap + strong). Measure the tier distribution for a week. Add the model classifier once you see the actual difficulty shape. This is the same approach we recommend in the OurToken docs: ship the simplest router that works, then let data drive the tuning.
FAQ
Does routing add latency?
A model-based classifier adds one small inference (50-150ms) before the main call. Rule-based classification adds near-zero latency. For most user-facing apps, the cost saving vastly outweighs the latency cost. For sub-second latency-critical paths, use rules only.
Which model should I use as the classifier?
A small, fast, cheap model. GPT-5.4-mini is ideal — it is good enough at one-word classification and costs almost nothing. Do not use your strong model as the classifier; that defeats the purpose.
How do I handle PII and compliance with routing?
Route through a single OpenAI-compatible endpoint that is already compliance-cleared, rather than calling multiple providers directly. This keeps data flow auditable in one place. See our models overview for the unified endpoint approach.
Can I route based on user tier too?
Yes. A common pattern is to route free-tier users more aggressively to cheap models and give paying users a higher strong-tier quota. This is just another input to the classifier — user plan becomes a routing signal alongside query difficulty.
What about streaming?
Streaming works identically — the router picks the tier, then streams from that model. The only addition is that on a mid-stream failure, you need a policy for whether to restart on the fallback tier or finish degraded. Most teams restart if fewer than 20% of tokens have streamed, otherwise finish degraded.